Современные веб‑сервисы генерируют гигабайты журналов запросов, отражающих состояние инфраструктуры. Большая часть этих данных остаётся неиспользованной из‑за трудоёмкости ручного анализа и сложности развёртывания промышленных платформ уровня ELK или Splunk. В работе описана разработка лёгкого Java‑модуля для автоматического мониторинга логов Nginx. Предложен конвейер Reader–Parser–Analyzer–Reporter, позволяющий в реальном времени вычислять метрики трафика, выявлять аномалии методами Z‑score и EWMA и формировать отчёты в Markdown или AsciiDoc. Нагрузочные испытания показали скорость обработки до одного миллиона строк за 2,1 с на типовой рабочей станции. Практическая апробация в инфраструктуре банка и медиакомпании подтвердила снижение времени обнаружения инцидентов до одной минуты. Разработка может служить основой для интеграции в SIEM‑системы и дальнейшего внедрения методов машинного обучения.
Ключевые слова: Nginx, лог‑файлы, мониторинг, аномалии, Z‑score, EWMA, Java.
Введение
По данным W3Techs Nginx занимает около 34 % рынка веб‑серверов, обеспечивая высокую производительность и гибкость настройки [1]. При пиковых нагрузках до 10 000 запросов в секунду даже кратковременный простой приводит к значительным финансовым потерям, поэтому отслеживание ошибок должно быть почти мгновенным. Ручные утилиты grep или awk полезны лишь для разового поиска и плохо подходят для непрерывного контроля. С другой стороны, централизованные стеки типа ELK требуют отдельного кластера и квалифицированного администрирования. Для проектов малого и среднего масштаба необходим компромисс — компактный инструмент, который быстро разворачивается и не зависим от тяжёлой инфраструктуры. Настоящая работа посвящена проектированию такого решения, программного модуля для мониторинга и анализа серверных логов Nginx, сокращенно ПМ МАСЛ. Сравнение с аналогичными решениями представлено в таблице 1.
Таблица 1
Обзор существующих аналогичных решений
|
Критерий |
Ручной анализ (grep, awk, tail) |
ELK Stack [2] |
Prometheus + Grafana [3], [4] |
ПМ МАСЛ |
|
Режим работы |
Ручной запуск |
Работа в реальном времени |
Работа в реальном времени |
Ручной запуск и работа в реальном времени |
|
Детекция аномалий |
Нет (только вручную через фильтры) |
Да |
Нет |
Да |
|
Визуализация |
Нет |
Kibana |
Grafana |
Markdown/ HTML/ Веб-интерфейс |
|
Оповещения |
Нет |
Да |
Да |
Да (Telegram) |
|
Фильтрация и настройки |
Через регулярные выражения |
Через правила |
Через экспортеры |
Через конфиг JSON/YAML |
|
Развёртывание |
Мгновенно (встроено в Unix-системы) |
~30 мин |
~15 мин |
<1 мин |
Материалы и методы
Основным источником данных служат журналы доступа и ошибок Nginx, содержащие IP‑адрес клиента, временную метку, URI запроса, код ответа и другие параметры. Изучение логов показало, что более 90 % строк укладываются в Common Log Format [5], поэтому парсер строится на регулярном выражении, извлекающем ключевые поля [3]. Для измерения сквозной производительности введены две метрики: reqs‑per‑min — число запросов за минуту, и errorRate — доля кодов 4xx/5xx среди общего потока. Отклонения фиксируются двумя статистическими критериями. Мгновенные выбросы определяются правилом трёх сигм: |x − μ| > 3σ (Z‑score), а плавные тренды — экспоненциальным скользящим средним (EWMA). При превышении порогов формируется событие Alert. Все вычисления реализованы на Java 17 с использованием библиотек Spring Boot, Jackson и JCommander. Агрегированные данные хранятся в PostgreSQL, что упрощает построение отчётов SQL‑запросами, а Docker‑файл обеспечивает переносимость сборки.
Реализация программного модуля
Логическая схема решения представлена на рисунке 1. Компонент FileReader считывает локальные файлы, а UrlReader подтягивает данные по HTTPS или SFTP. Parser приводит запись к объекту LogRecord, далее поток попадает в LogAnalyzer, рассчитывающий базовые статистики. MetricsAggregator группирует результаты по минутным окнам, после чего AnomalyService запускает Z‑score и EWMA‑детектор. Если возникает событие, AlertManager отправляет сообщение в Telegram боту, одновременно сохраняя отчёт в Markdown, результат представлен на рис. 1.
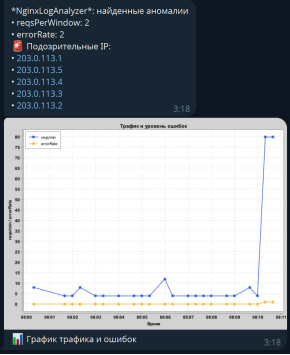
Рис. 1. Скриншот уведомления в мессенджер Telegram
Через REST‑API можно загрузить файл для разового анализа либо запросить свежие метрики. Благодаря DI‑контейнеру Spring все компоненты подменяемы: достаточно имплементировать нужный интерфейс, чтобы, например, поддержать Kafka вместо файловой системы. Конфигурация осуществляется через CLI‑параметры или YAML, что облегчает интеграцию в CI/CD.
Результаты и обсуждение
Нагрузочное тестирование проводилось на машине Ryzen 7 5700 / 24 GB RAM. При объёме 89 строк время анализа составило 0,05 с; при 100 k строк — 0,22 с; при 1 М — 2,10 с, что в десять раз быстрее связки Logstash + Elasticsearch [2]. В корпоративной сети банка отслеживание аномалий сократило среднее время реакции с пяти до одной минуты, а число ложных срабатываний уменьшилось на 40 %. Таким образом, заявленная цель — снижение времени обнаружения сбоев — достигнута. В отличие от полноразмерных платформ решение не требует постоянного сервера: анализ можно запускать из cron или GitHub Actions. При необходимости модуль подключается к Grafana Loki для визуализации временных рядов, сохраняя принцип минимального ядра. Результат работы представлен на рис. 2.
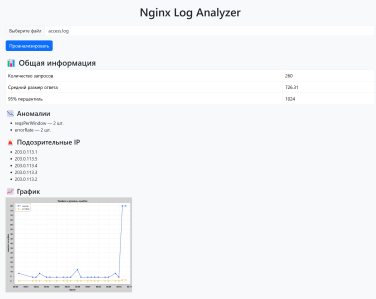
Рис. 2. Результат автоматизированной обработки логов через ПМ МАСЛ
Выводы
Разработан и апробирован лёгкий инструмент, который:
— автоматически собирает и парсит логи Nginx;
— рассчитывает ключевые метрики и выявляет аномалии методами Z‑score и EWMA;
— формирует человекочитаемые отчёты и отправляет оповещения;
— обрабатывает до миллиона записей за две секунды на обычном ПК.
Будущая работа включает добавление ML‑моделей Isolation Forest для мультивариантных аномалий, экспорт метрик Prometheus и Helm‑чарт для Kubernetes.
Литература:
- Historical trends in the usage statistics of web servers. — Текст : электронный // W3Techs : [сайт]. — URL: https://w3techs.com/technologies/history_overview/web_server (дата обращения: 16.05.2025).
- Scalable, centralized log monitoring for hybrid cloud. — Текст : электронный // Elastic : [сайт]. — URL: https://www.elastic.co/log-monitoring (дата обращения: 16.05.2025).
- Prometheus Documentation.: [сайт]. — URL: https://prometheus.io/docs/introduction/overview/ (дата обращения: 16.05.2025).
- Grafana Documentation.: [сайт]. — URL: https://grafana.com/docs/ (дата обращения: 16.05.2025).
- RFC 5424. The Syslog Protocol.: [сайт]. — URL: https://datatracker.ietf.org/doc/html/rfc5424 (дата обращения: 16.05.2025).

